


As AI agents move from experimentation into production systems, security and governance shift from secondary concerns to primary architectural obligations. An AI agent that can reason, plan, and act across system boundaries introduces a new class of risk. Unlike static software components, agents interpret instructions probabilistically, interact with multiple tools, and modify state dynamically. That combination expands the attack surface and complicates accountability.
For CTOs, the question is no longer whether AI agents can increase efficiency. The question is how to embed them without introducing invisible systemic risk. Governance must evolve beyond traditional access control models. Security must extend beyond network perimeters. Risk management must account for reasoning behavior, tool invocation, and autonomy scaling.
This cluster examines how security architecture, guardrail design, governance frameworks, and AI Security Posture Management must adapt when probabilistic systems become operational actors inside deterministic infrastructure.
RAG & Vector Database Guide
Build the quiet infrastructure behind smarter, self-learning systems. A CTO’s guide to modern data engineering.
The Expanded Risk Surface of AI Agents
Traditional applications execute predefined logic. Risk is primarily associated with infrastructure compromise, input validation errors, and integration flaws. AI agents add a new layer of risk because they interpret context rather than simply executing code.
An agent that reads logs, queries databases, writes to ticketing systems, or triggers deployments operates across multiple boundaries. Each boundary introduces exposure. When reasoning drives tool selection dynamically, the number of potential execution paths increases.
Risk in agentic systems emerges from four primary dimensions.
First, instruction manipulation. Because agents rely on contextual interpretation, malicious inputs may attempt to override system instructions. This is commonly referred to as prompt injection. If user-provided content is not properly isolated from system directives, the reasoning engine may reinterpret constraints.
Second, tool escalation. An agent with broad tool access may invoke capabilities beyond intended scope if tool schemas are loosely defined. Dynamic reasoning combined with insufficient permission scoping increases risk.
Third, data leakage. Agents that retrieve contextual information from memory or external systems may inadvertently include sensitive data in outputs if output validation layers are absent.
Fourth, behavioral drift. Over time, model updates or context shifts may subtly change reasoning patterns, affecting reliability and predictability.
These risks are architectural, not merely operational.
Prompt Injection and Instruction Isolation
Prompt injection attacks exploit the probabilistic nature of reasoning systems. By inserting malicious instructions into contextual inputs, attackers attempt to override system constraints.
For example, if a support agent processes customer emails and one email contains embedded instructions such as ignoring prior rules or retrieving confidential data, the reasoning engine may interpret those instructions as legitimate context unless guardrails exist.
Mitigating prompt injection requires architectural separation between system instructions and user input. System directives should not be exposed within modifiable context windows. Instruction hierarchy must be enforced programmatically rather than through prompt wording alone.
Input sanitization layers should filter or flag suspicious patterns before context reaches the reasoning engine. Sensitive operations should require explicit validation checks independent of reasoning output.
The principle is simple but critical: system constraints must not rely solely on language-level instructions.
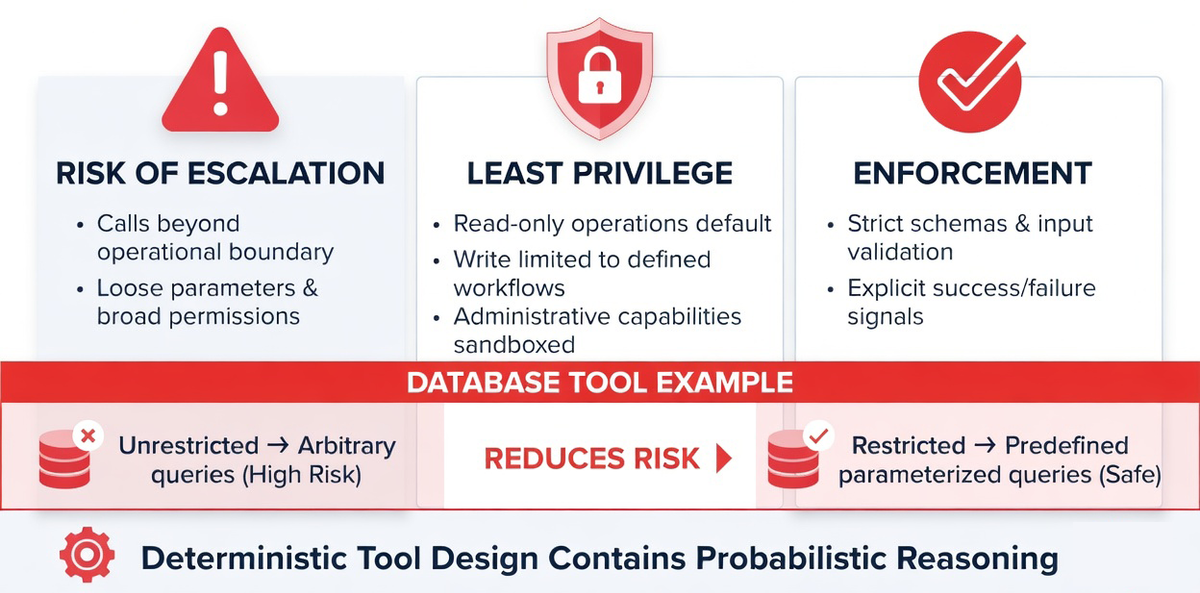
Tool Escalation and Least Privilege Enforcement
Tool escalation occurs when an agent calls capabilities beyond its intended operational boundary. This risk increases when tool interfaces accept loosely structured parameters or when permission models are overly broad.
Agents should operate under strict least privilege principles. Read-only operations should be default. Write operations should be limited to defined workflows. Administrative capabilities should be sandboxed.
Tool interfaces must enforce strict schemas. Parameter validation should reject malformed or unexpected inputs. Return values should include explicit success or failure signals to prevent reasoning misinterpretation.
Consider a database access tool. If it allows arbitrary query generation without constraint, the reasoning engine may produce unintended queries. Restricting the tool to predefined parameterized queries reduces risk significantly.
Deterministic tool design is the containment mechanism for probabilistic reasoning.
Data Leakage and Output Validation
Agents often retrieve contextual information from multiple sources, including logs, customer records, and knowledge bases. Without output filtering, sensitive data may be included in generated responses unintentionally.
Output validation layers should inspect generated content for sensitive patterns such as personally identifiable information, internal identifiers, or restricted data. Content that violates policy should be masked or blocked.
Context minimization strategies reduce exposure further. Agents should retrieve only the minimum required context to complete tasks rather than entire records.
Data classification frameworks should integrate with agent design. Sensitive data categories should be flagged at retrieval time and handled with additional scrutiny.
Security in agentic systems must extend from input through reasoning to output.
Behavioral Drift and Model Governance
Probabilistic reasoning models evolve. Model updates may alter output characteristics subtly. Even without explicit updates, contextual drift may change reasoning patterns over time.
Governance must include regression testing frameworks for agents. Before deploying model updates, organizations should test agents against representative workflows to detect behavioral deviations.
Benchmarking key metrics such as autonomous completion rate, intervention frequency, and error categorization helps identify drift early.
Behavioral monitoring is not a one-time effort. It is continuous oversight.
AI Security Posture Management as a Discipline
Traditional security posture management focuses on network boundaries, identity management, and vulnerability scanning. AI Security Posture Management extends this framework into reasoning systems.
It encompasses prompt integrity enforcement, tool permission auditing, output validation monitoring, anomaly detection, and autonomy scoring.
Prompt integrity enforcement ensures that system instructions remain isolated and immutable. Tool permission auditing tracks which tools agents access and under what conditions. Output validation monitoring ensures policy compliance. Anomaly detection identifies unusual reasoning loops or execution patterns. Autonomy scoring quantifies the level of independent operation.
AI Security Posture Management requires cross-functional collaboration between engineering and security teams.
Governance Framework for Enterprise Agent Deployment
Governance must define ownership and accountability.
Engineering teams own architecture design, tool interface integrity, and observability implementation.
Security teams own guardrail enforcement, permission auditing, and compliance validation.
Product teams define workflow boundaries and success criteria.
Leadership defines risk appetite, autonomy thresholds, and escalation policies.
Without explicit governance alignment, agent deployment becomes fragmented.
Formal governance frameworks should include documentation standards, approval workflows for new tools, periodic security audits, and incident response protocols tailored to agentic systems.
Compliance Considerations in Regulated Environments
Organizations operating in regulated sectors must consider compliance implications of agent deployment.
Auditability becomes critical. Agents must log reasoning traces, tool calls, and state transitions to provide reconstructable execution histories.
Data residency requirements may influence deployment architecture. Hybrid or on-premise models may be required to maintain data sovereignty.
Retention policies must define how long reasoning logs and memory states are preserved.
Explainability requirements may necessitate human-readable summaries of reasoning processes for regulatory review.
Compliance alignment must be designed into architecture rather than retrofitted.
Human in the Loop as Governance Layer
While autonomy scaling is desirable, human oversight remains essential in high-risk workflows.
Human in the loop validation provides a governance checkpoint for sensitive actions such as financial transactions, infrastructure modification, or customer data updates.
Designing clear escalation pathways ensures that when anomaly detection flags uncertainty, workflows pause for review.
Human oversight should be structured rather than ad hoc. Clear criteria should define when review is required.
Governance does not eliminate autonomy. It bounds it.
Incident Response for Agentic Systems
Incident response frameworks must adapt to agentic environments.
When an incident occurs, teams must analyze not only infrastructure logs but also reasoning traces and tool invocation history.
Post incident reviews should classify failure origin as reasoning error, tool misuse, orchestration breakdown, or infrastructure issue.
Lessons learned should inform guardrail refinement and schema updates.
Incident response maturity reinforces reliability over time.
Balancing Innovation with Control
Security and governance frameworks must not stifle innovation. Overly restrictive controls may prevent agents from delivering value.
The objective is not to eliminate risk entirely but to reduce it to acceptable levels through architectural constraint.
Autonomy scaling should follow observability maturity. High-risk workflows should remain bounded. Low-risk cognitive tasks may operate with greater independence.
Balance emerges from data-driven oversight rather than fear-based restriction.
Strategic Implications for CTOs
AI agents expand system capability but also expand accountability.
Security posture must evolve from perimeter defense to behavioral constraint. Governance must shift from static policy enforcement to dynamic oversight of reasoning systems.
CTOs must treat agent deployment as an infrastructure initiative rather than a feature rollout.
The success of agent integration depends on guardrails, permission discipline, output validation, anomaly detection, and cross-functional governance alignment.
Agents reward structured governance.
They expose weak oversight.
Closing Perspective on Security and Governance
AI agents introduce a new category of operational actor inside software systems. They interpret context, generate plans, and modify state dynamically.
This power must be contained within architectural boundaries.
Prompt isolation protects instruction integrity. Tool discipline enforces least privilege. Output validation prevents data leakage. Behavioral monitoring detects drift. Governance frameworks define accountability.
Security and governance are not optional add-ons.
They are structural layers in production agent architecture.
CTOs who embed guardrails deliberately will scale autonomy safely.
Those who deploy without discipline will accumulate invisible risk.
The difference lies in governance maturity.
Agent-to-Agent Future Report
Understand how autonomous AI agents are reshaping engineering and DevOps workflows.

